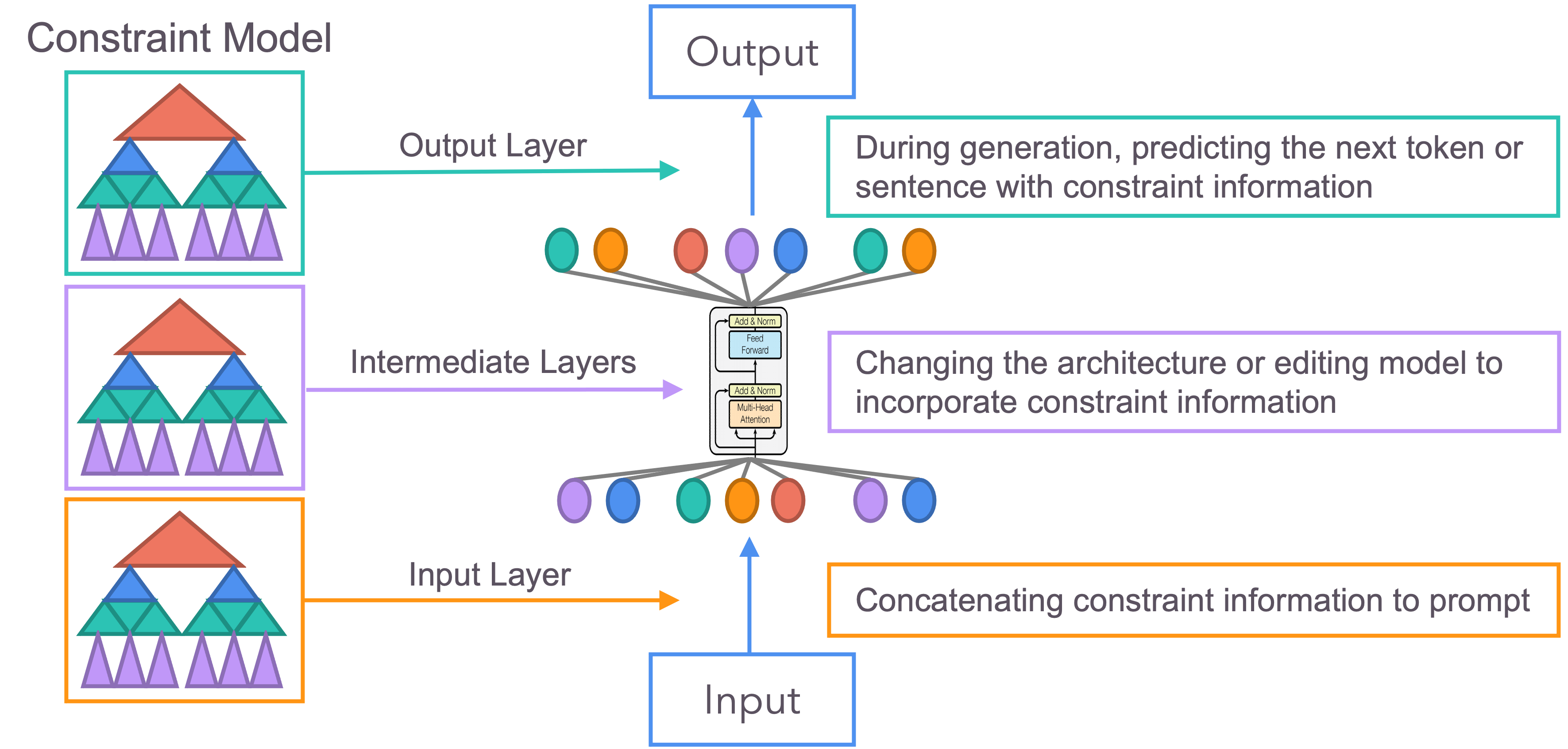
COLM: Consistent Language Models
Large language models often return results that are inconsistent with the commons sense or domain knowledge, so called hallucinations. This significantly reduces their reliability and undermines their applications. COLM builds novel, usable, and efficient techniques to ensure that output of language and foundation models follow rules and knowledge in the domain.
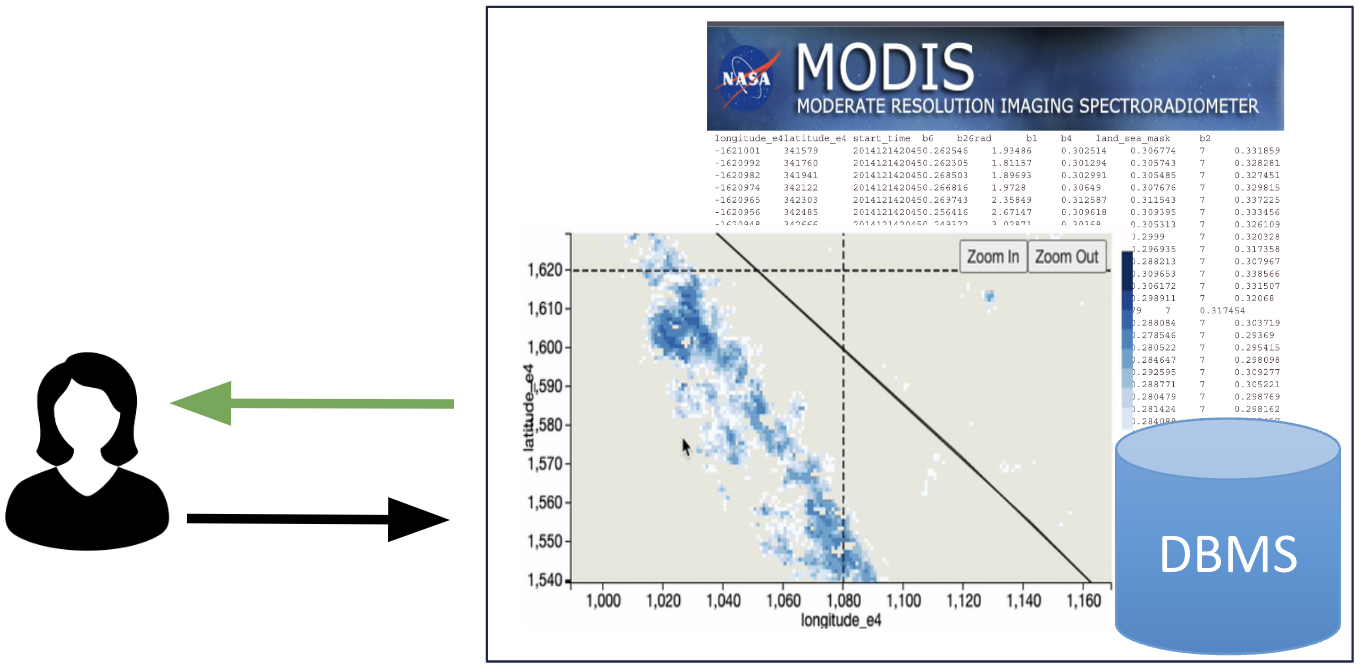
HUDL: Human-Data Collaboration
HUDL aims at building interactive data-centric systems that collaborate with humans to achieve common goals, e.g., training ML models or exploring data for novel patterns. These systems identify and adapt to the human’s learning and reasoning so their collaboration converge to the desired results quickly.
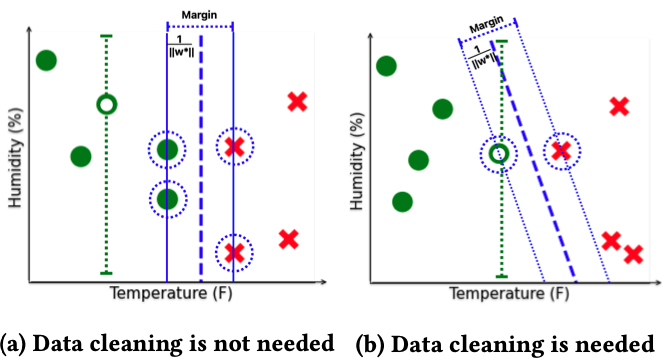
RAD: Reasoning and ML On Raw Data
Raw data is usually dirty , e.g., missing or inconsistent information, and needs substantial amounts of resources to clean. Data cleaning is a major obstacle in ML and inference on large data. In this project, we propose novel methods to learn accurate models over dirty data without cleaning.
AutoD: Autonomous Data Integration
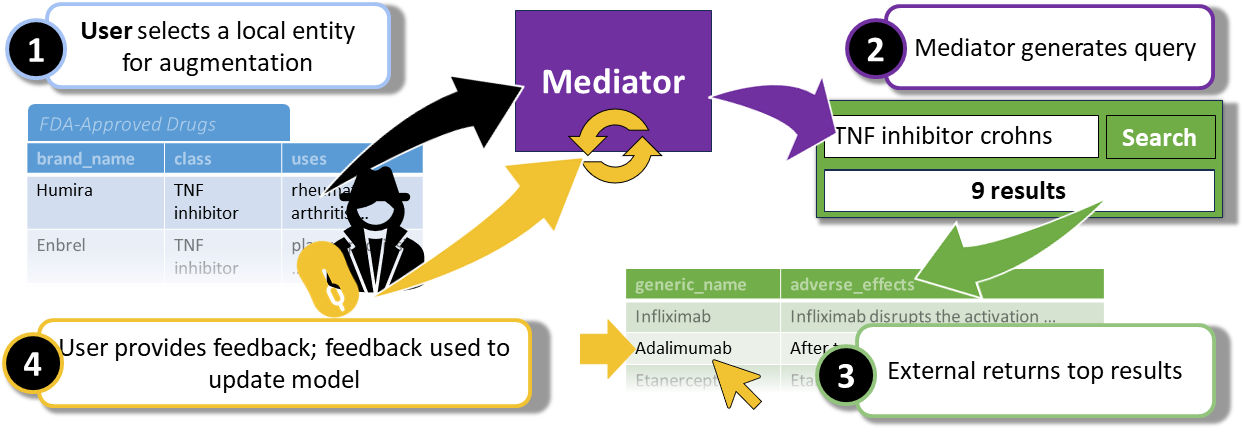
Users often need to integrate information from multiple data sources. AutoD proposes autonomous systems that without any or with minimal expert intervention and progressively discovers and integrates relevant information from multiple data sources. It leverages end users' feedback to learn how to retrieve information relevant to each entity in a dataset from external data sources.
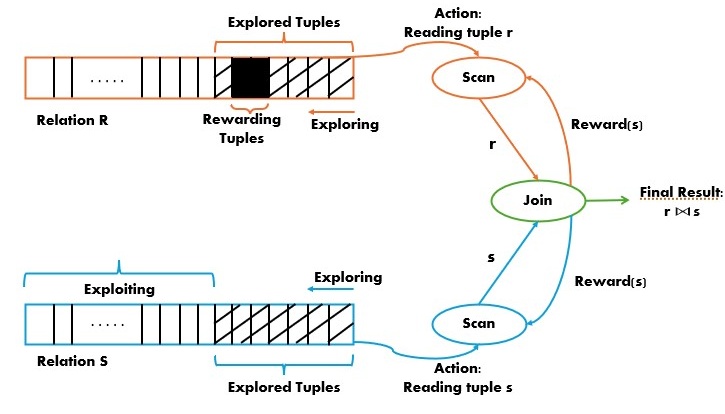
MAQS: Multi-Agent Query Processing
Users need quick access to results of query, which is difficult to achieve with large datasets. Current query processing algorithms are often not able to satisfy users' desired running time as they require time and resource intensive pre-processing or support only limited types of queries, e.g., equi-joins. MAQS proposes a novel approach to query processing in which operators of each query collaborate and learn toghether to discover an efficient query processing strategy.