
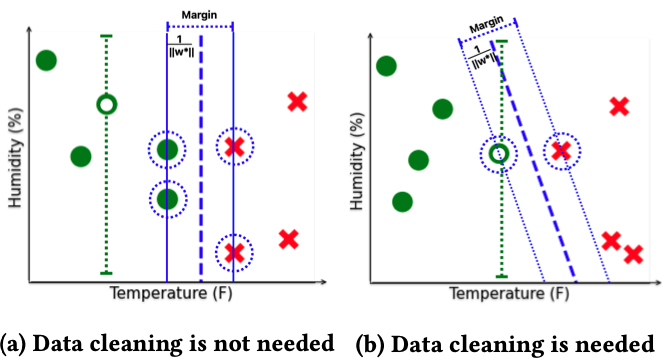
Raw data is usually dirty , e.g., missing or inconsistent information, and needs substantial amounts of resources to clean. Data cleaning is a major obstacle in ML and inference on large data. In this project, we propose efficient methods to learn accurate models or infer accurate results over dirty data without cleaning.
Publications
-
Minimal Data Cleaning for Model Training by MinPrep [To appear in PVLDB 2026]
Cheng Zhen, Prayoga, Nischal Aryal, Arash Termehchy, Alireza Aghasi
-
Minimal Repairs for Learning Over Incomplete Data [BibTex]
Cheng Zhen, Nischal Aryal, Arash Termehchy, Prayoga, Garrett Biwer
NeurIPS Workshop on Reliable ML from Unreliable Data, 2025.
-
Learning Accurate Models on Incomplete Data with Minimal Imputation [Code+Data] [BibTex]
Cheng Zhen, Nischal Arya, Arash Termehchy, Prayoga, Garrett Biwer, and Sankalp Patil
arXiv:2503.13921 [cs.LG], March 2025
-
Certain and Approximately Certain Models for Statistical Learning [Slides] [Code+Data] [BibTex]
Cheng Zhen, Nischal Aryal, Arash Termehchy and Amandeep Singh Chabada
The Proceedings of the ACM on Management of Data (SIGMOD), Article 126, 2024
-
When Can We Ignore Missing Data in Model Training? [Slides][Code+Data]
Cheng Zhen, Amandeep Singh Chabada, Arash Termehchy
In Proceedings of SIGMOD Workshop on Data Management for End-to-End Machine Learning (DEEM), June 2023.
-
Learning Over Dirty Data Without Cleaning [Slides][Code+Data]
Jose Picado, John Davis, Arash Termehchy, and Claire Lee
The Proceedings of SIGMOD, 2020.
Technical report with proofs
-
Learning Efficiently Over Heterogenous Databases [Poster]
Jose Picado, Sudhanshu Pathak, and Arash Termehchy
The Proceedings of the VLDB Endowment (Demonstration Track) , August 2018.
People
-
Arash Termehchy
-
Cheng Zhen
-
Nischal Aryal
-
Jose Picado
-
Amandeep Singh Chabada
-
John Davis
-
Claire Lee